PDF dosyaları her yerdedir. İşletmeler onları sözleşme ve rapor hazırlamak için kullanır, öğrenciler ders notlarını saklamak için onlara güvenir ve araştırmacılar akademik makaleleri sık sık PDF olarak paylaşır. PDF’ler biçimi korumak için harika olsa da düzenleme, arama, analiz etme veya içeriği yeniden kullanma açısından zorlayıcı olabilir.
İşte bu yüzden birçok kullanıcı PDF’yi metne dönüştürmek ister.
PDF’den metin çıkardığınızda içeriği düzenleyebilir, belgeleri yapay zekâ ile özetleyebilir, bilgileri daha verimli arayabilir ve statik dosyaları kullanılabilir bilgiye dönüştürebilirsiniz. İster dijital PDF’lerle ister taranmış belgelerle çalışıyor olun, modern araçlar bu süreci her zamankinden daha kolay hâle getiriyor.
Bu rehberde PDF’yi metne dönüştürme sürecini, ne zaman OCR gerektiğini, en iyi araçları ve yapay zekânın belge işlemeyi nasıl değiştirdiğini öğreneceksiniz.
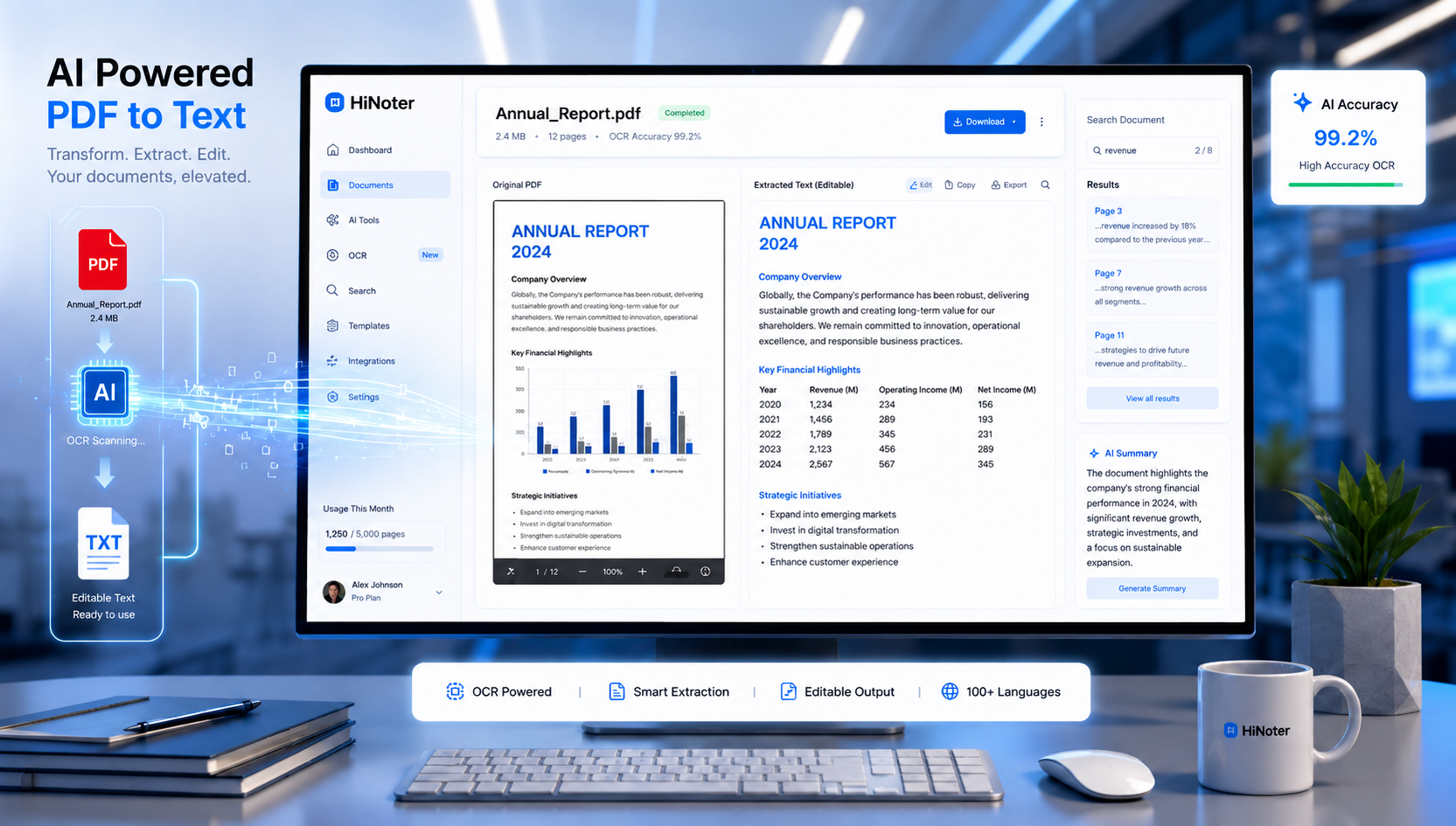
Neden insanlar PDF’yi metne dönüştürmek ister
PDF, belgelerin farklı cihazlar ve işletim sistemleri arasında biçimini korumak için tasarlanmıştır. Ancak bu tutarlılık, içeriğin yeniden kullanılmasını da zorlaştırabilir.
PDF’yi metne dönüştürdüğünüzde şu avantajları elde edersiniz:
Başlıca avantajlar
| Avantaj | Neden önemlidir? |
|---|---|
| Daha Kolay Düzenleme | Belgeleri yeniden oluşturmadan içeriği değiştirin |
| Daha Hızlı Arama | Bilgiyi anında bulun |
| Yapay Zekâ Analizi | Özetler ve içgörüler üretin |
| İçeriği Yeniden Kullanma | Raporları makalelere veya notlara dönüştürün |
| Daha İyi Erişilebilirlik | Yardımcı araçlarla uyumluluğu artırın |
| Veri Çıkarma | Bilgileri diğer sistemlere aktarın |
Öğrenciler, profesyoneller ve araştırmacılar için PDF’yi düzenlenebilir metne dönüştürmek, saatler süren manuel işi ortadan kaldırabilir.
Farklı PDF Türlerini Anlamak
Bir dönüştürme yöntemi seçmeden önce, PDF dosyalarının iki ana kategorisini anlamak önemlidir.
Metin Tabanlı PDF’ler
Bu dosyalar zaten makine tarafından okunabilen metin içerir.
Örnekler:
- PDF olarak dışa aktarılan Word belgeleri
- Dijital raporlar
- E-kitaplar
- Çevrimiçi kılavuzlar
- İş sunumları
Bu dosyalardan metin çıkarma işlemi genellikle hızlı ve son derece doğrudur.
Taranmış PDF’ler
Taranmış PDF’ler, esasen bir PDF kapsayıcısı içinde saklanan görüntü dosyalarıdır.
Örnekler:
- Taranmış sözleşmeler
- Basılı kitaplar
- Tarihî arşivler
- El yazısı belgeler
- Kâğıt formlar
Dosyanın içinde gömülü gerçek metin bulunmadığından, yazılımın metni çıkarmadan önce görüntüdeki karakterleri tanıması gerekir.
Bu süreç OCR teknolojisine dayanır.

Yapay Zekâda OCR Nedir?
OCR, Optik Karakter Tanıma anlamına gelir.
OCR teknolojisi, görüntüler içindeki harfleri, rakamları ve sembolleri tanımlar ve bunları düzenlenebilir metne dönüştürür.
Geleneksel OCR onlarca yıldır var, ancak modern yapay zekâ destekli OCR sistemleri çok daha gelişmiştir.
Yapay Zekâ Destekli OCR Neler Yapabilir?
- Birden çok dili tanıyabilir
- Belge yapısını algılayabilir
- Tabloları çıkarabilir
- Başlıkları belirleyebilir
- El yazısı içeriği işleyebilir
- Tanıma hatalarını otomatik olarak düzeltebilir
Yapay zekâ modelleri yalnızca karakterleri tanımakla kalmaz, belgelerin bağlamını da anlar.
Bu nedenle birçok kullanıcı artık geleneksel OCR yazılımına güvenmek yerine PDF’yi yapay zekâ ile metne dönüştürme iş akışlarını destekleyen çözümleri tercih ediyor.
Geleneksel OCR ve Yapay Zekâ OCR Karşılaştırması
| Özellik | Geleneksel OCR | Yapay Zekâ OCR |
|---|---|---|
| Karakter Tanıma | İyi | Mükemmel |
| El Yazısı Desteği | Sınırlı | Gelişmiş |
| Düzeni Koruma | Temel | Güçlü |
| Tablo Çıkarma | Zayıf | Doğru |
| Hata Düzeltme | Manuel | Yapay Zekâ Destekli |
| Çoklu Dil Desteği | Orta | Mükemmel |

OCR ile Taranmış PDF Metne Nasıl Dönüştürülür?
Taranmış belgelerde metin çıkarılmadan önce OCR uygulanmalıdır.
Şu adımları izleyin:
1. Adım: PDF’yi Yükleyin
Aşağıdakiler gibi OCR destekli bir araç seçin:
- Adobe Acrobat
- Google Drive OCR
- Microsoft OneDrive
- HiNoter
- ABBYY FineReader
2. Adım: OCR İşlemini Çalıştırın
Yazılım her sayfayı tarar ve metin öğelerini belirler.
OCR motorları genellikle şunları yapar:
- Karakterleri algılar
- Cümleleri yeniden oluşturur
- Biçimlendirmeyi korur
- Belge yapısını tanımlar
3. Adım: Sonuçları Gözden Geçirin
Şunları kontrol edin:
- İsimler
- Tarihler
- Sayılar
- Tablolar
- Özel biçimlendirmeler
Gelişmiş OCR sistemleri bile zaman zaman hata yapabilir.
4. Adım: Metni Dışa Aktarın
Yaygın dışa aktarma biçimleri şunlardır:
- TXT
- DOCX
- Markdown
- HTML
Bu aşamada PDF dosyasını metne dönüştürme iş akışınız tamamlanmış olur.
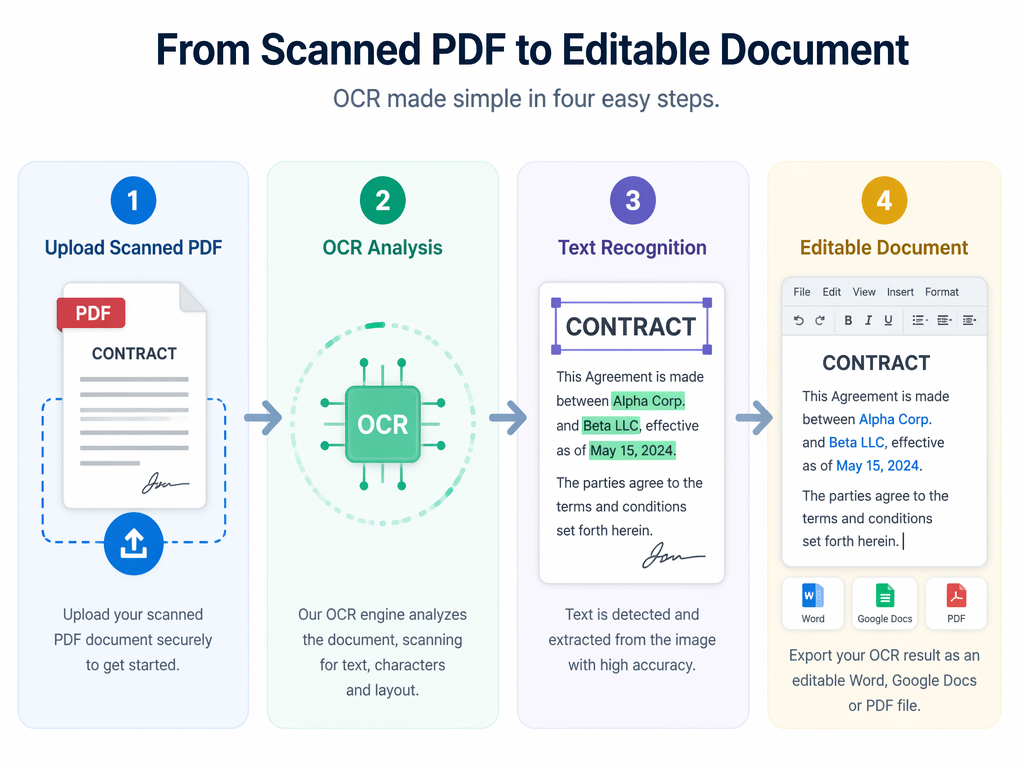
PDF’yi Ücretsiz Olarak Metne Nasıl Dönüştürebilirim?
Birçok kullanıcı yalnızca ara sıra dönüştürme yapar ve özel yazılımlar için ödeme yapmak istemez.
Neyse ki birkaç ücretsiz çözüm mevcuttur.
Popüler Ücretsiz Yöntemler
| Araç | Ücretsiz Sürüm | OCR Desteği |
|---|---|---|
| Google Docs | Evet | Temel |
| Adobe Online Tools | Sınırlı | Evet |
| Microsoft OneDrive | Evet | Temel |
| Tesseract OCR | Evet | Gelişmiş |
| HiNoter | Freemium | Yapay Zekâ OCR |
Birçok kullanıcı kuruluma gerek duymadığı ve doğrudan tarayıcıda çalıştığı için çevrimiçi PDF’den metne dönüştürme aracını tercih eder.
Ücretsiz Çözümlerin Avantajları
- Yazılım kurulumu gerekmez
- Hızlı kurulum
- Her cihazdan erişim
- Basit işler için uygundur
Sınırlamalar
- Dosya boyutu kısıtlamaları
- Daha düşük OCR doğruluğu
- Dışa aktarma sınırlamaları
- Daha az yapay zekâ özelliği
Büyük belge iş akışlarında, özel yapay zekâ destekli araçlar genellikle çok daha iyi sonuç verir.
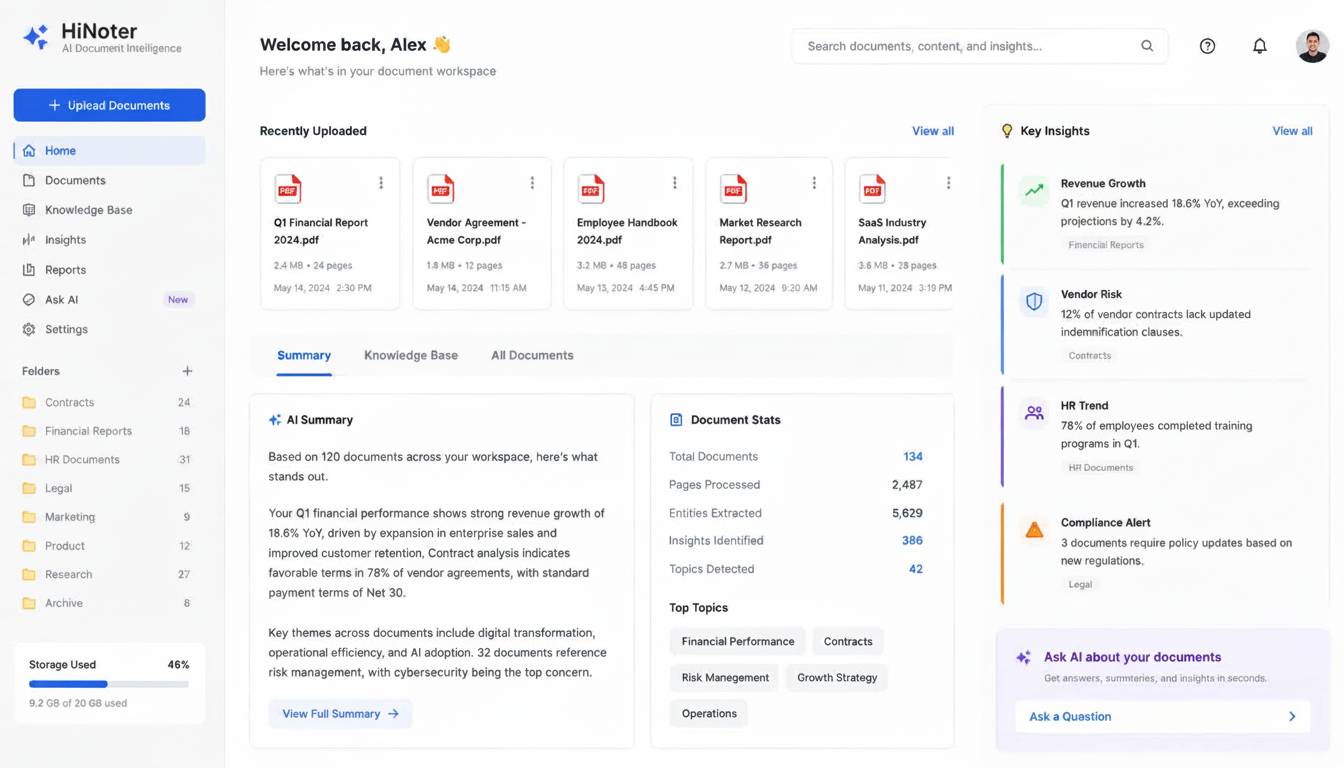
PDF’yi Metne Nasıl Dönüştürürüm?
Süreç, PDF’nizin metin tabanlı mı yoksa taranmış mı olduğuna bağlıdır.
Yöntem 1: Mevcut Metni Kopyalama
Metin tabanlı PDF’ler için:
- Dosyayı açın
- İçeriği seçin
- Metni kopyalayın
- Bir belge düzenleyicisine yapıştırın
Yöntem 2: OCR ile Dönüştürme
Taranmış belgeler için:
- PDF’yi yükleyin
- OCR’yi etkinleştirin
- Metni çıkarın
- Sonuçları gözden geçirin
- Dışa aktarın
Yöntem 3: Yapay Zekâ Destekli Dönüştürme
Modern yapay zekâ araçları şunları yapabilir:
- Metin çıkarma
- Bölümleri düzenleme
- Özet oluşturma
- Temel içgörüleri belirleme
- Aranabilir notlar üretme
Bu yaklaşım, büyük hacimde belge yöneten profesyoneller arasında giderek daha popüler hâle geliyor.
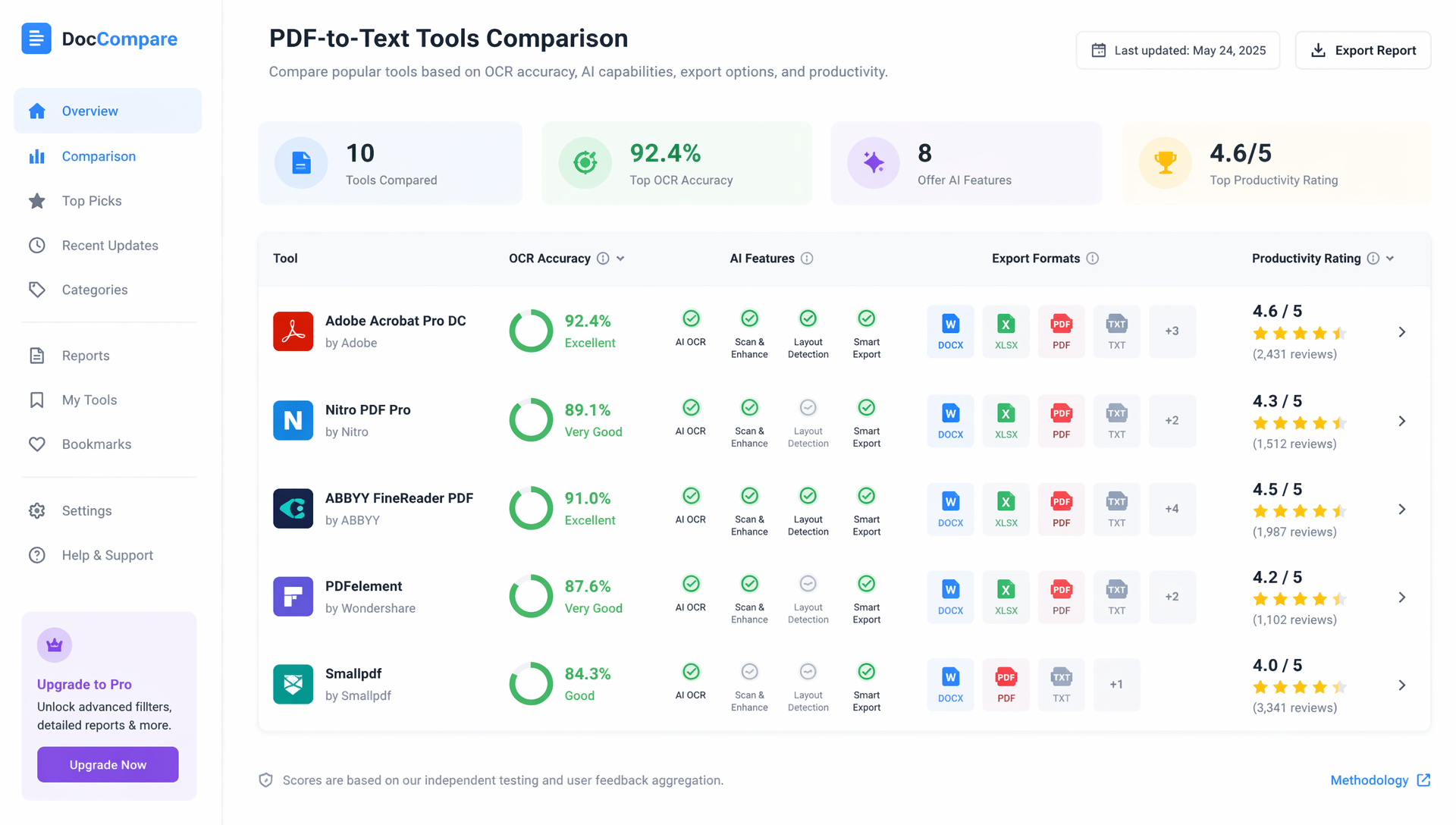
En İyi PDF’den Metne Dönüştürme Araçları
Piyasada çok çeşitli PDF dönüştürme çözümleri bulunur.
Karşılaştırma Tablosu
| Araç | OCR Kalitesi | Yapay Zekâ Özellikleri | Ücretsiz Plan | En Uygun Olduğu Alan |
|---|---|---|---|---|
| HiNoter | Mükemmel | Mükemmel | Evet | Yapay zekâ verimliliği |
| Adobe Acrobat | Mükemmel | İyi | Sınırlı | Profesyonel belgeler |
| Google Docs | Temel | Hayır | Evet | Gündelik kullanıcılar |
| ABBYY FineReader | Mükemmel | Orta | Hayır | Kurumsal OCR |
| Microsoft OneDrive | Temel | Hayır | Evet | Microsoft ekosistemi |
Nelere Dikkat Etmelisiniz?
Bir dönüştürücü seçerken şunları göz önünde bulundurun:
- OCR doğruluğu
- Desteklenen diller
- Dışa aktarma seçenekleri
- Yapay zekâ yetenekleri
- Gizlilik korumaları
- İşleme hızı
Her kullanıcı kurumsal düzeyde OCR’ye ihtiyaç duymaz, ancak sözleşmeler, araştırma makaleleri veya iş belgeleriyle çalışırken doğruluk çok daha önemli hâle gelir.
Yapay Zekâ Belge İşlemeyi Nasıl Dönüştürüyor?
Geleneksel dönüştürücüler çıkarma işlemine odaklanır.
Modern yapay zekâ platformları ise anlamaya odaklanır.
Yapay zekâ sistemleri yalnızca PDF’yi Metne Dönüştürmeye yardımcı olmakla kalmaz, belge içeriğini analiz ederek eyleme dönüştürülebilir içgörüler de sunabilir.
OCR’nin Ötesindeki Yapay Zekâ Yetenekleri
- Özetleme
- Ana nokta çıkarma
- Soru yanıtlama
- Anlamsal arama
- Not oluşturma
- Bilgi düzenleme
Bu gelişim, işletmelerin bilgiyi işleme biçimini değiştirdi.
Örnek Yapay Zekâ İş Akışı
| Adım | Yapay Zekâ Eylemi |
|---|---|
| PDF Yükleme | Belge yapısını analiz et |
| OCR | Metni çıkar |
| Anlama | Konuları ve bölümleri belirle |
| Özetleme | Kısa özetler oluştur |
| Arama | Anında erişim sağla |
Bu nedenle PDF’yi yapay zekâ ile metne dönüştürme çözümlerine olan ilgi eğitim, araştırma ve iş dünyasında artmaya devam ediyor.
PDF Dönüştürmede Sık Karşılaşılan Zorluklar
En iyi araçlar bile bazı zorluklarla karşılaşır.
Düşük Tarama Kalitesi
Düşük çözünürlüklü taramalar OCR doğruluğunu azaltır.
Karmaşık Düzenler
Şunları içeren belgeler:
- Tablolar
- Çok sütunlu düzenler
- Grafikler
- Karma medya
daha zor işlenebilir.
El Yazısı İçerik
El yazısı tanıma gelişmeye devam etse de daktilo edilmiş metne göre hâlâ daha zordur.
Birden Fazla Dil
Bazı OCR motorları çok dilli belgelerde zorlanır.
Yüksek kaliteli bir OCR platformu seçmek sonuçları önemli ölçüde iyileştirir.
Metni Tekrar PDF’ye Dönüştürebilir misiniz?
İlginç şekilde, bilgiyi çıkaran birçok kullanıcı daha sonra PDF belgelerini yeniden oluşturmak ister.
İşte bu noktada metni ücretsiz çevrimiçi PDF’ye dönüştürme araçları işe yarar.
Çoğu belge düzenleyici kullanıcılara şunları yapma imkânı verir:
- Metin belgeleri oluşturmak veya düzenlemek
- İçeriği biçimlendirmek
- Doğrudan PDF olarak dışa aktarmak
Popüler seçenekler şunlardır:
- Google Docs
- Microsoft Word
- Canva
- Adobe Acrobat
- Çevrimiçi PDF oluşturucular
Bu sayede iş akışınıza bağlı olarak düzenlenebilir metin ile PDF biçimi arasında kolayca geçiş yapabilirsiniz.
Doğru Sonuçlar İçin En İyi Uygulamalar
PDF dönüştürme kalitesini artırmak için:
Yüklemeden Önce
- Yüksek çözünürlüklü taramalar kullanın
- Sayfaların düzgün hizalandığından emin olun
- Gölge veya parlamadan kaçının
- İyi ışıkta tarayın
Çıkardıktan Sonra
- İsimleri ve tarihleri doğrulayın
- Sayısal değerleri kontrol edin
- Tabloları dikkatle inceleyin
- Orijinal dosyalarla karşılaştırın
Küçük doğrulama adımları doğruluğu büyük ölçüde artırabilir.

SSS
PDF’yi ücretsiz olarak metne nasıl dönüştürebilirim?
Google Docs, Microsoft OneDrive OCR, Adobe’nin çevrimiçi araçları veya freemium yapay zekâ platformlarını kullanabilirsiniz. Bu seçenekler, yazılım satın almadan metin çıkarmanıza olanak tanır.
Yapay zekâda OCR nedir?
OCR (Optik Karakter Tanıma), görüntüler içindeki metni düzenlenebilir içeriğe dönüştüren bir teknolojidir. Yapay zekâ destekli OCR, belge yapısını ve bağlamı anlayarak doğruluğu artırır.
OCR ile taranmış PDF metne nasıl dönüştürülür?
Taranmış dosyayı OCR özellikli bir araca yükleyin, belgeyi işleyin, çıkarılan içeriği gözden geçirin ve metni tercih ettiğiniz biçimde dışa aktarın.
En iyi PDF’den metne dönüştürücü hangisidir?
En iyi çözüm ihtiyaçlarınıza bağlıdır. Temel işler için ücretsiz OCR araçları yeterli olabilir. Gelişmiş belge anlama için HiNoter gibi yapay zekâ destekli platformlar OCR, özetler ve aranabilir bilgi yönetimini tek bir iş akışında sunar.
PDF’yi metne nasıl dönüştürürüm?
Metin tabanlı PDF’lerde içeriği doğrudan kopyalayabilirsiniz. Taranmış PDF’lerde ise düzenlenebilir metin çıkarmak için OCR yazılımı veya yapay zekâ destekli belge işleme araçlarını kullanın.
Son Düşünceler
PDF’ler modern iş akışlarında en önemli belge biçimlerinden biri olmaya devam ediyor, ancak değerli bilgiler çoğu zaman statik dosyaların içinde hapsoluyor.
PDF’yi Metne Dönüştürme yeteneği, belgeleri düzenlemeyi, analiz etmeyi, aramayı ve organize etmeyi kolaylaştırır. İster sözleşmeler, akademik makaleler, iş raporları veya taranmış arşivlerle çalışıyor olun, doğru dönüştürme yöntemini seçmek ciddi zaman ve emek tasarrufu sağlar.
Yapay zekâ OCR’yi ve belge anlamayı geliştirmeye devam ettikçe, PDF işleme geleceği basit metin çıkarmanın ötesine geçerek akıllı bilgi yönetimine yöneliyor. Modern araçlar artık PDF’leri aranabilir ve eyleme dönüştürülebilir bilgiye çevirebiliyor; böylece kullanıcılar daha hızlı çalışıp her belgeden daha fazla değer elde edebiliyor.